The ugrep file pattern searcher
a more capable compatible grep replacement -- search for anything in everything... fast!
ugrep release 7.8 Star
ugrep installs on
fast and reliable
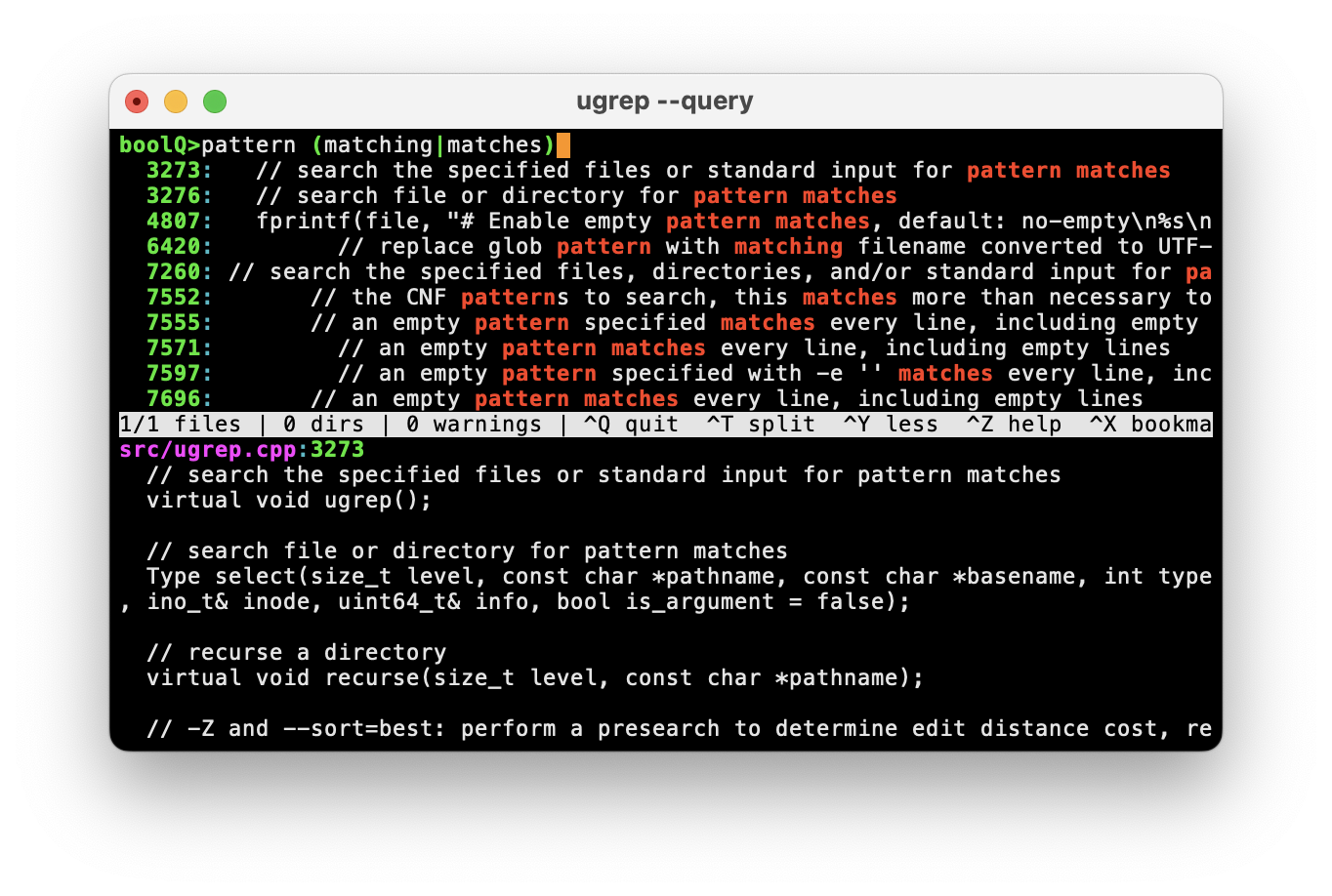
Why use ugrep?
Search fast with enhanced grep command options and with the built-in TUI (shown). Google search files with logic patterns (shown), fuzzy search, search (nested!) zip/7z/tar/pax/cpio archives, tarballs and compressed files gz/Z/bz/bz2/lzma/xz/lz4/zstd/brotli, search and hexdump binary files, and search documents, such as PDF, doc, docx. Output results like grep or in JSON, XML, CSV or your own customized format. Offers rich Unicode extended regex pattern syntax, PCRE regex syntax, and multi-line pattern matching without requiring any special command-line options.
Commands
Search for patterns in files with the ug and ugrep commands, where
- ug
- for user-friendly use, with an optional .ugrep configuration file with your preferences located in the working directory or in your home directory;
the ug+ command also searches pdfs, documents, e-books, image metadata
- ug --save-config OPTIONS
- saves a new .ugrep file in the working directory using the current .ugrep configuration and by copying the relevant OPTIONS (if any) to the new .ugrep file
- ugrep
- does not use a .ugrep configuration file and does not set default options:
ugrep works best in shell scripts;
the ugrep+ command also searches pdfs, documents, e-books, image metadata
Examples:
- ug -Q
- start the interactive query TUI then enter patterns to recursively search for matching files, press F1 or CTRL-Z for help and options, press ALT-L to list matching files (option -l)
- ug -%% -jwQ
- recursively Google search files with AND/OR/NOT patterns (option -%%) with smart ignore case (option -j) regex patterns matching words (option -w) in the interactive query TUI (option -Q)
- ug PATTERN
- recursively search for files matching PATTERN; a recursive search is performed when no search targets are specified
- ug PATTERN FILE
- search lines in FILE matching PATTERN
- ug PATTERN DIR
- search files in DIR matching PATTERN, excluding sub-directories (like
ls DIR takes a DIR to list)
- ug -r PATTERN DIR
- recursively search files in DIR matching PATTERN, excluding symlinks
- ug -rS PATTERN DIR
- recursively search files in DIR matching PATTERN, including symlinks to files (option -S), but not to directories
- ug -R PATTERN DIR
- recursively search files in DIR matching PATTERN, including symlinks to files and directories
- ug -3 PATTERN DIR
- recursively search files in DIR matching PATTERN using -r up to 3 levels, i.e. DIR/, DIR/one/, and DIR/one/two/
- ug -3 -g"foo*.txt" PATTERN DIR
- recursively search for filenamess matching glob foo*.txt (option -g) as an inclusive search constraint in DIR using -r up to 3 levels
- ug -z PATTERN
- recursively search for files, archives and compressed files matching PATTERN
- ug -z -tc,cpp -Z PATTERN
- recursively search for files, archives and compressed files (option -z) for C and C++ source file types (option -t) that fuzzy match PATTERN (option -Z)
- ug -z -l "" package.zip
- list (option -l) files in archive package.zip (option -z) using an empty pattern "" to match all (or use option --match)
- ug -z -W --pager "" mailattachment.zip
- safely page through the contents of mailattachment.zip (option -z), hexdump binary contents (option -W) to reveal data
- ug PATTERN -Opem --filter="pem:openssl x509 -passin pass: -text -in %
- recursively find files with suffix .pem (option -O), then use openssl as a filter to search the certificate data
- ug --save-config --ignore-files --ignore-binary --decompress
- save a .ugrep configuration file that lets ug obey .gitignore rules in recursive searches, ignore binary files (-I) in searches and always search archives and compressed files (-z)
- ug --help regex
- get help on regex or specify an option name or a word to get help with
Also...
- the regex pattern syntax is standard POSIX ERE, same as
egrep, but supporting full Unicode matching by default
- patterns match Unicode and may include newline breaks \n and \R to match multiple lines as a single match; for example the pattern "foo.*\n.*\n.*baz" matches a line with foo, a second line and a third line with baz, the pattern "foo(.*\n)*?.*bar" lazily matches one or more lines from foo to bar
- quote "PATTERN" or 'PATTERN' to prevent globbing by the shell that may expand *, ? and [a-z] into pathnames
- Windows Command Prompt does not parse ' to quote patterns; you must use " instead
- Windows PowerShell does not parse "" (empty pattern); you must specify --match instead
- an empty pattern "" matches every line, same as option --match
- multiple FILE and DIR pathname arguments may be specified as search targets; if none are provided, the working directory is recursively searched
- standard input is searched if standard input is not a terminal, such as a pipe redirect
- to replace GNU/BSD grep with an alias of ugrep for the command-line: alias grep='ug -G'; alias egrep='ug -E'; alias fgrep='ug -F'; alias zgrep='ug -zG'; alias zegrep='ug -zE'; alias zfgrep='ug -zF'
- to replace GNU/BSD grep binaries for scripting: copy or symlink
ugrep to grep, egrep, fgrep, zgrep, zegrap, zfgrep to a directory on your PATH; ugrep automatically emulates these grep executables according to these names; important: copy ugrep instead of symlink when using bash as a shell!
Options
Ugrep is compatible with GNU/BSD grep command-line options to lower the learning curve when using ugrep as a replacement. But ugrep offers many new options and featues. Command-line options can be mixed and specified in any order. Long options --OPTION may start with --no-OPTION to disable them. All short options have long alternatives. This page shows short options for the most part. Specify --stats to output a final summary search report of options, patterns, and search statistics.
List matching files
- -l
- list matching files
- -l -m5,
- list files that have at least 5 matching lines (-m5, with the comma is the same as --min-count=5)
- -l --max-files=3
- list only the first 3 matching files
- -L
- list non-matching files, same as -lv i.e. option -v inverts matching
- -c
- count matching lines in files
- -cv
- count non-matching lines in files; option -v inverts matching
- -cu
- count all pattern matches by ungrouping multiple matches from lines (option -u)
- -cm1,
- count matching lines in files, but skip files with zero matches (-m1, with comma is --min-count=1)
Also...
- if you never want -c to output zero match counts, then add min-count=1 to your ~/.ugrep file (outputing zero match counts is a GNU grep behavior)
- to disable directory tree-based listings, specify --no-tree or permanently add no-tree to your ~/.ugrep file
- listings are sorted by name; to sort by date/time or by size, specify --sort=changed or --sort=size
Displaying matches, match info, match context
- -H
- always output the filename; normally, a filename is not output when searching a single specified file
- -n
- output the line number of a match
- -k
- output the column number of a match; specify --tabs=NUM to set the tab size to 1 (no expansion), 2, 4 or 8 (default)
- -b
- output the byte offset of a match
- -u
- ungroup multiple matches from lines to count and output each match separately
- -C3
- output matching lines with 3 lines as context before (option -B3) and after (option -A3)
- -y
- output matching lines with the rest of the file as context (--any-line or --passthru)
- -o
- output only the matching part
- -o -C20
- output only the matching part with the matching line as context before (option -B20) and after (option -A20) to fit 40 characters
- --width
- truncate lines to the terminal window width; --width=40 truncates to 40 characters
Pattern matching modes
- -F
- search for matching strings, not regex patterns, like GNU
fgrep or grep -F
- -G
- BRE pattern syntax, like GNU
grep or grep -G
- -P
- Perl regex pattern search with PCRE, see also ug --help regex
- -Z
- fuzzy search with the default ERE pattern syntax
- -U
- non-Unicode ASCII/binary search; patterns such as \xa3 match a byte, not the U+00a3 multi-byte code point
- -Y
- empty-matching patterns such as x*y*z* match all lines like GNU/BSD grep, instead of returning useful matches
- -i
- ignore case in matching patterns
- -j
- smart ignore case, enables -i when patterns are specified in lower case
- -w
- patterns must match as words and not be part of words
- -x
- patterns must match whole lines from start to end
- -v
- invert pattern matching; output lines that do not match
- -e PATTERN
- explicitly specify PATTERN; -e is used to specify multiple patterns and when specifying a pattern after the FILE argument
- -N PATTERN
- do not match PATTERN when combined with -e; for example -e "[0-9]+" -N "0+" matches nonzero numbers
- -f FILE
- read additional patterns from FILE
- -f cpp/names
- if cpp/names is not a local file, then read built-in C++ name-matching patterns (installed in /.../share/ugrep/patterns/cpp/names)
The interactive TUI
- -Q
- start TUI to specify search patterns and options interactively
- -Q -e PATTERN
- start TUI and search for PATTERN
- -Q -e PATTERN --view=nano
- start TUI to search for PATTERN, press CTRL-Y to edit a matching file at the first matching line with nano
Also...
- options, files and directories are taken from the command line to start the TUI search
- ALT-key toggles the option letter corresponding to the key press, for example ALT-L lists matching files (option -l) and SHIFT-ALT-C shows context (option -C3)
- ALT-key in MacOS terminal is OPTION-key when "Use Option as Meta key" is enabled in Terminal Preferences/Profiles/Keyboard
- ALT-key in xterm may not work unless xterm*metaSendsEscape: true is added to ~/.Xdefaults
- navigate to directories and files with Tab, then SHIFT-Tab to go back and restore previous options and patterns (if changed)
- use the cursor keys, PgUp, PgDn and the scroll wheel to scroll the search results
- ALT-G glob editor to match filenames and directories (globs ending in /) or exclude them with ! for example !tmp/
- CTRL-S jumps to the next context match, the next matching file or the next directory in the list, CTRL-W jumps back
- CTRL-T or F5 toggles the split screen file viewer; option --split starts the TUI with the split screen
- CTRL-X or F3 sets a bookmark and CTRL-R or F4 restores it
- CTRL-Y or F2 displays a file in a pager, a specific pager or editor is specified with option --view=PAGER
- CTRL-Z or F1 displays help and the active search options that can be toggled on/off with ALT-key or just key
- ENTER enters output selection mode to select lines to output when exiting the TUI (selections are kept until TUI exits or until a new search is performed)
Googling files with logic patterns
- -% "foo bar"
- space is AND: search files for lines matching both regex patterns foo and bar anywhere on the same line
- -%% "foo bar"
- space is AND: find files matching both patterns foo and bar anywhere in the same file (-%% is the same as --bool --files)
- -% "foo -bar"
- space-dash is AND NOT: search files for lines matching pattern foo that do not match bar anywhere on the same line
- -%% "foo -bar"
- space-dash is AND NOT: find files matching pattern foo that do not match bar anywhere in the same file (-%% is the same as --bool --files)
- -% "foo bar|baz"
- space is AND, | is OR: search files for lines matching both patterns foo and bar|baz anywhere on the same line
- -% "foo -(bar|baz)"
- space-dash is AND NOT, | is OR: search files for lines matching pattern foo that do not match bar|baz anywhere on the same line
- -% "foo AND NOT (bar OR baz)"
- same as above, this time using AND OR NOT operators
- -% "foo -bar -baz"
- same as above, in normalized conjungctive normal form (ugrep internally normalizes logic to CNF)
- -% 'foo "-bar baz"'
- search files for lines matching both patterns foo and -bar baz, where "-bar baz" is quoted to match literally "as is"
- -F -% "*foo* bar?"
- search files for lines matching both fixed (option -F) strings *foo* and bar? anywhere on the same line
Also...
- white space in a pattern is a logical AND (lowest precedence)
- a | in a pattern is a logical OR (taking higher precedence than AND)
- a - in a pattern with spacing is a logical NOT (taking highest precedence)
- the keywords AND, OR and NOT may also be used when properly spaced
- quote strings in a pattern with " to match literally "as is"
- group patterns with ( ) parentheses
- option -% (or --bool) can be combined with any pattern matching modes -F, -G, -P, -Z and other options
- the default search mode is --lines for option -% to match lines
- option -%% (or --bool --files) matches across entire files, like how a search engine returns results
- option --stats reports the normalized pattern logic to search files
Fuzzy search
- -Z
- approximately match patterns up to one extra, missing or replaced character in the input
- -Z2
- approximately match patterns up to two extra, missing or replaced characters in the input
- -Z+2
- approximately match patterns up to two extra characters in the input
- -Z-2
- approximately match patterns up to two missing characters in the input
- -Z~2
- approximately match patterns up to two replaced characters in the input
- -Z+-2
- approximately match patterns up to two extra or missing characters in the input
- -Z+-~2
- same as -Z2: approximately match patterns up to two extra, missing or replaced characters in the input
- -c -Z
- count approximate matches in files
- -c -Zbest2
- count -Z2 approximate matches in files, but only keep the best matches, i.e. if a file has at least one exact match, then only exact matches are counted
- -c -Zbest2 --sort=best
- count the best approximate matches in files and sort by best matching files for each (sub)directory searched
Also...
- the first character or characters that make up a pattern always match; to approximately match the first character(s), replace it with a . or .?
- no whitespace may be given between -Z and its argument
- when
ugrep is installed as replacement binaries for GNU/BSD grep, egrep fgrep, zgrep, zegrep or zfgrep, option -Z is automatically reassigned to --null for GNU/BSD grep compatibility; use grep --fuzzy instead for fuzzy search
Archives and compressed files
- -z
- also search zip/7z/tar/pax/cpio archives, tarballs and gz/Z/bz/bz2/lzma/xz/lz4/zstd/brotli compressed files
- -z --zmax=2
- also search archives, tarballs and compressed files stored within archives (max 2 levels)
- -z -I --zmax=2
- same as above, but ignore binary files and also those in (nested) archives and compressed files
- -z -tc,cpp
- search C and C++ source files and also those in archives, see also ug -tlist for a list of file types
- -z -g"*.txt,*.md"
- search files matching the globs *.txt and *.md and also those in archives, see also ug --help globs
- -z -g"^bak/"
- exclude all bak directories from the search and skip those in archives, see also ug --help globs
Also...
- when option -g, -O, -M, or -t is specified, searches archives for files that match the specified globs, file extensions, file signature magic bytes, or file types, respectively; as a side-effect, these options restrict the selection of compressed files and archives searched to only those files with filename extensions that match known compression and archive types (for example, .jar is a non-standard zip file extension and not searched unless -Ojar is specifies also)
- to let
ug always search archives and compressed files, add decompress to your ~/.ugrep file
- when
ugrep is installed as replacement binaries for GNU/BSD grep, egrep fgrep, zgrep, zegrep or zfgrep, option -z is automatically reassigned to --null-data for GNU/BSD grep compatibility; use zgrep, zegrep, zfgrep instead
Binary files and devices
- -I
- ignore binary files and exclude them from searches
- -W
- hexdump binary matches, while keeping text matches as text
- -X
- hexdump all matches
- -U --hexdump
- hexdump 8-bit binary regex pattern matches instead of Unicode character-based patterns (option -U)
- --hexdump=4a
- hexdump in 4 columns and output a * for hex lines that are identical to the previous line (a)
- --hexdump=4ch
- hexdump in 4 columns, no character column (c), no hex spacing (h)
- --hexdump=4C3
- hexdump in 4 columns with 3 hex lines of context before and after (C3 or B3A3)
- --hexdump=4C3 -u -b
- same as above, but ungroup matches (option -u) and output the byte position of each match (option -b)
- -Dread
- also read special devices to search them; danger: can get stuck on a non-responsive device!
Also...
- option -U disables Unicode in regex patterns; patterns such as \xa3 match a single byte, not the Unicode U+00a3 code point
- option --hexdump takes an optional argument of the form [1-8][a][bch][A[NUM]][B[NUM]][C[NUM]] to output 1, 2, 3 or up to 8 columns of hexadecimal octets (default is 2), a outputs a * for all hex lines that are identical to the previous hex line, b removes all space breaks, c removes the character column, h removes hex spacing, A includes up to NUM hex lines after a match, B includes up to NUM hex lines before a match and C includes up to NUM hex lines before and after a match.
Exclusions and inclusions
- -@
- (--all) search all files except hidden: cancel previous restrictions; restrictions specified after this option are still applied, e.g. -@I searches all non-binary files
- -.
- (--hidden) include hidden files in searches; normally, hidden files are excluded from searching
- -I
- ignore binary files and exclude them from searches
- -p
- never follow symlinks, even when specified on the command line
- -r
- search recursively without following symlinks
- -rS
- search recursively following symlinks to files, but not to directories (option -S)
- -R
- search recursively following symlinks to files and directories
- -tc,cpp
- only search C and C++ source files, see also ug -tlist for a list of file types
- -Ohpp,cpp
- shorthand for -g"*.hpp,*.cpp" with filename extension globs to search .hpp and .cpp files
- -g"*.hpp,*.cpp"
- only search .hpp and .cpp files with the specified glob patterns, see also ug --help globs
- -g"src/"
- only recursively search src directories with the specified glob pattern ending in a / for directories, see also ug --help globs
- -g"^*.txt,^bak/"
- do not search .txt files and bak directories with the specified negated glob patterns, see also ug --help globs
- --iglob="^*.txt,^bak/"
- same as above, but with case-insensitive glob matching (option --glob-ignore-case applies to all globs)
- -K10,99
- only search files from line 10 up to and including line 99
- -m1
- output only the first matching line (same as --max-count=1)
- -m2,9
- only search files with at least two matching lines and output up to and including 9 matching lines
- -m2,9 -u
- only search files with at least two matches and output up to and including 9 matches
- -3
- recursively search up to three directory levels deep, i.e. one/, one/two/, and one/two/three/
- -2-3
- only recursively search sub-directories at two to three levels deep, i.e. one/two/, and one/two/three/
- --max-files=3
- only return matches for the first three matching files (in the current --sort order)
- --max-size=1mb
- only return matches for files with physical sizes 1MB or smaller, the specified size may use `kb`(ilo), `mb`(ega), `gb`(iga), `tb`(era) suffix
- --min-size=100
- only return matches for files with physical sizes of 100 bytes or larger, the specified size may use `kb`(ilo), `mb`(ega), `gb`(iga), `tb`(era) suffix
- --ignore-files
- obey gitignore rules in recursive searches using local .gitignore files along directory search paths
- --ignore-files=FILE
- obey gitignore rules in recursive searches using local FILE along directory search paths
- --exclude-from=FILE
- exclude files or directories specified as globs in FILE, see also ug --help globs
- --include-from=FILE
- only search the files and directories specified as globs in FILE, see also ug --help globs
- --from=FILE
- read additional pathnames of files to search from FILE
- --filter="COMMANDS"
- filter files first before searching them by executing a utility on a file based on its type, see also ug --help filter
- --exclude-fs=PATH
- do not search the file system associated with PATH (a mounted directory or mount point)
- --exclude-fs
- only descend into the file systems associated with the specified file and directory search targets, exclude all other
- --include-fs=.
- only search the file system associated with . (. is the PATH), i.e. ignores all mounted and special devices
Also...
- a - (dash) for a FILE argument of an option, such as --from=-, reads from standard input
- to let ug ignore binary files by default, add ignore-binary to your ~/.ugrep file
- to let ug obey .gitignore rules in recursive searches by default, add ignore-files to your ~/.ugrep file
Formatted output
- --csv
- CSV output format
- --json
- JSON output format
- --xml
- XML output format
- --format="FORMAT"
- custom output formatting, see also ug --help format
Also...
- formatting can be combined with other options, such as -n to include line numbers
- see custom output formatting for a list of format fields to specify in a --format="FORMAT" argument
Pretty things, more or less
- --pretty
- enable -n, -T, --color, --tree, --heading, --break and --sort when output is sent to a terminal
- --tree
- list files in a directory tree for options -l and -c
- --heading
- output the file name as a heading of a matching file
- --break
- output an empty line between matching files
- -T
- tabulate line and column numbers to add spacing
- --color
- colorize the output when displayed on a terminal (default)
- --colors=COLORS
- specify a color pallette COLORS, see also ug --help colors
- --hyperlink=+
- embed hyperlinks in the output when sent to a terminal, with linked line/column numbers when =+ is specified
- --pager
- output to a pager, default is more or less
- --pager=COMMAND
- output to COMMAND as a pager
- --tag
- output matches as ___match___ instead of colorizing them, where --tag=TAG,TAG outputs TAGmatchTAG
- --replace="FORMAT"
- replace matches in the output by FORMAT, see also ug --help format
- --separator=SEP
- specify SEP to separate line and column numbers from the match
- --group-separator=SEP
- specify SEP to separate context for options -ABC
- --width
- truncate lines to the terminal window width; --width=40 truncates to 40 characters
Also...
ug enables --pretty and --sort by default
ugrep only enables --color by default
Getting help
- --help WHAT
- display help on WHAT you are looking for
- --help regex
- display help in detail on regex patterns
- --help globs
- display help in detail on glob patterns, e.g. for option -g
- --help format
- display help in detail on output formatting with option --format and --replace
Regex
| . | any character except \n |
| a | the character a |
| ab | the string ab |
| a|b | a or b |
| a* | zero or more a's |
| a+ | one or more a's |
| a? | zero or one a |
| a{3} | 3 a's |
| a{3,} | 3 or more a's |
| a{3,7} | 3 to 7 a's |
| a*? | zero or more a's lazily |
| a+? | one or more a's lazily |
| a?? | zero or one a lazily |
| a{3}? | 3 a's lazily |
| a{3,}? | 3 or more a's lazily |
| a{3,7}? | 3 to 7 a's lazily |
| a(b|cd?) | ab or ac or acd |
| \. | escapes . to match . |
| \Q...\E | the literal string ... |
| \f | form feed |
| \n | newline |
| \r | carriage return |
| \R | any Unicode line break |
| \t | tab |
| \v | vertical tab |
| \X | any character and \n |
| \cZ | control character ^Z |
| \0 | NUL |
| \0ddd | octal character code ddd |
| \xhh | hex character code hh |
| \x{hhhh} | Unicode code point U+hhhh |
| \u{hhhh} | Unicode code point U+hhhh |
| [abc-e] | one character a,b,c,d,e |
| [^abc-e] | one char not a,b,c,d,e,\n |
| [[:alnum:]] | a letter or decimal digit |
| [[:alpha:]] | a lower or uppercase letter |
| [[:ascii:]] | ASCII char \x00-\x7f |
| [[:blank:]] | a space or a tab |
| [[:cntrl:]] | a control character |
| [[:digit:]] | a decimal digit |
| [[:graph:]] | a visible character |
| [[:lower:]] | a lowercase letter |
| [[:print:]] | a visible char or space |
| [[:punct:]] | a punctuation character |
| [[:space:]] | a space,\t,\v,\f,\r |
| [[:upper:]] | an uppercase letter |
| [[:word:]] | a word-like character |
| [[:xdigit:]] | a hexadecimal digit |
| \p{Class} | one character in Class |
| \P{Class} | one char not in Class |
| \d | a decimal digit |
| \D | a non-digit character |
| \h | a space or a tab |
| \H | not a space or a tab |
| \l | a lowercase letter |
| \L | a non-lowercase character |
| \s | a whitespace except \n |
| \S | a non-whitespace |
| \u | an uppercase letter |
| \U | a non-uppercase character |
| \w | a word-like character |
| \W | a non-word character |
| ^ | begin of line anchor |
| $ | end of line anchor |
| \A | begin of file anchor |
| \Z | end of file anchor |
| \b | word boundary |
| \B | non-word boundary |
| \< | start of word boundary |
| \> | end of word boundary |
| (?#...) | comments ... are ignored |
| (...) | group |
| patterns that require option -P |
|---|
| (...) | capturing group |
| (?:...) | non-capturing group |
| (?=...) | lookahead |
| (?!...) | negative lookahead |
| (?<=...) | lookbehind |
| (?<!...) | negative lookbehind |
| (?<X>...) | capturing group name X |
| \3 | matches group 3 |
| \g{10} | matches group 10 |
| \g{X} | matches group name X |
- ERE (Extended Regular Expression) syntax is the default in ugrep (shown in the table), like GNU
egrep or grep -E
- ERE syntax is also used with option -P for PCRE (Perl regular expressions), adding lookaround and group capture patterns
- BRE (Basic Regular Expression) syntax with option -G requires the \-escaped syntax \| for |, \+ for +, \? for ?, \( \) for ( ), and \{ \} for { }
- option -U disables Unicode in regex patterns and speeds up searching; patterns such as \xa3 match a byte, not the U+00a3 multi-byte code point
- character classes such as \s and negated classes such as [^abc-e] never match a newline \n which is implicitly removed for GNU grep compatibility
- explicitly specify a \n or a \R in a pattern such as "go[\s\n]up" to match multiple lines as a single match
- mutiple classes are combined in a single bracket list, such as [.[:xdigit:]\s] to combine . wtih hexadecimal digits and space
- subtract classes in a bracket list with [\w--[\d]] or intersect classes in a bracket list with [\w&&[\d]] which is just \d
- for \p{Class} (match one character in Class) and for \P{Class} (match one character not in Class) a Unicode Class is one of:
| ASCII | any ASCII character |
| Unicode | any Unicode character except \n |
| Non_ASCII_Unicode | any non-ASCII Unicode character |
| Alpha | Ll or Lu, same as [[:alpha:]] |
| Alnum | Ll or Lu or Nd, same as [[:alnum:]] |
| Space | Zs or \t,\v,\f,\r whitespace, same as \s or [[:space:]] |
| Word | L or Nd or Pc, same as \w or [[:word:]] |
| L& | Ll or Lu or Lt |
| L or Letter | Ll or Lu or Lt or Lm or Lo |
| M or Mark | Mn or Mc or Me |
| Z or Separator | Zs or Zl or Zp |
| S or Symbol | Sm or Sc or Sk or So |
| N or Number | Nd or Nl or No |
| P or Punctuation | Pd or Ps or Pe or Pi or Pf or Pc or Po, same as [[:punct:]] |
| C or Other | Cc or Cf, same as [[:cntrl:]] |
| Ll or Lower or Lowercase_Letter | a lower case letter, same as \l or [[:lower:]] |
| Lu or Upper or Uppercase_Letter | an upper case letter, same as \u or [[:upper:]] |
| Lt or Titlecase_Letter | a title case letter |
| Lm or Modifier_Letter | a modifier letter |
| Lo or Other_Letter | any other letter |
| Mn or Non_Spacing_Mark | a nonspacing mark |
| Mc or Spacing_Combining_Mark | a spacing mark |
| Me or Enclosing_Mark | an enclosing mark |
| Zs or Space_Separator | a space separator |
| Zl or Line_Separator | a line separator |
| Zp or Paragraph_Separator | a paragraph separator |
| Sm or Math_Symbol | a math symbol |
| Sc or Currency_Symbol | a currency symbol |
| Sk or Modifier_Symbol | a modifier symbol |
| So or Other_Symbol | any other symbol |
| Nd or Decimal_Digit_Number | a decimal number, same as \d or [[:digit:]] |
| Nl or Letter_Number | a letter number |
| No or Other_Number | any other number |
| Pd or Dash_Punctuation | a dash punctuation |
| Ps or Open_Punctuation | an open punctuation |
| Pe or Close_Punctuation | a close punctuation |
| Pi or Initial_Punctuation | an initial punctuation |
| Pf or Final_Punctuation | a final punctuation |
| Pc or Connector_Punctuation | a connector punctuation |
| Po or Other_Punctuation | any other punctuation |
| Cc or Control | a control character |
| Cf or Format | a format character |
| UnicodeIdentifierStart | L or Nl |
| UnicodeIdentifierPart | L or Nl or Mn or Mc or Nd or Cf or IdentifierIgnorable |
| IdentifierIgnorable | U+0000~0008,000E~001B,007F,0080~009F |
| JavaIdentifierStart | L or Nl or Sc or Pc |
| JavaIdentifierPart | L or Nl or Sc or Pc or Mn or Mc or Nd or Cf |
| CsIdentifierStart | L or Nl or Pc or '@' |
| CsIdentifierPart | L or Nl or Pc or Mn or Mc or Nd or Cf |
| PythonIdentifierStart | a start of Python identifier character |
| PythonIdentifierPart | a Python identifier character |
| IsBlock | a character in the specified Unicode Block |
| Language | a character in the specified Language |
Globs
Ugrep supports gitignore-style globbing for all glob-related options -g, --iglob=, --exclude=, --include=, -include-dir=, --exclude-dir=, --include-from=, --exclude-from=, and --ignore-files, where
| * | matches anything except / |
| ? | matches any one character except / |
| [abc-e] | matches one character a,b,c,d,e |
| [^abc-e] | matches one character not a,b,c,d,e,/ |
| [!abc-e] | matches one character not a,b,c,d,e,/ |
| / | when used at the start of a glob, matches the working directory |
| **/ | matches zero or more directories on a path |
| /** | when at the end of a glob, matches all paths after the / |
| \? | matches a ? or any other character specified after the backslash |
- --ignore-files globs ignore both file and directory names that match per gitignore rules, whereas all other globbing-related options match directory names only when a glob ends with a /
- to prevent the shell from expanding globs, you must quote globs like "*.cpp" in command-line options such as -g"*.cpp",
- a glob pattern starting with a ^ or a ! inverts matching: instead of matching a filename or directory name, the directory or file is ignored and excluded from the search
- when a glob pattern contains a /, the full pathname is matched, otherwise, the basename of a file or directory is matched in recursive searches
- when a glob pattern starts with a /, the glob matches file and directory names from the working directory path, not recursively
- when a glob pattern ends with a /, the glob matches directory names, not filenames
File types
The -t or --file-type= argument is a comma-separated list of file types. A file type is associated with one or more filename extensions, internally using option -O to match filename extensions. For capitalized file types, the search is expanded to include files with matching file signature magic bytes, internally using option -M. When a type is preceded by a ! or a ^, excludes files of the specified type.
| actionscript | = | -O as,mxml |
| ada | = | -O ada,adb,ads |
| adoc | = | -O adoc |
| asm | = | -O asm,s,S |
| asp | = | -O asp |
| aspx | = | -O master,ascx,asmx,aspx,svc |
| autoconf | = | -O ac,in |
| automake | = | -O am,in |
| awk | = | -O awk |
| Awk | = | -O awk |
| | | -M '#!\h*/.*\Wg?awk(\W.*)?\n' |
| basic | = | -O bas,BAS,cls,frm,ctl,vb,resx |
| batch | = | -O bat,BAT,cmd,CMD |
| bison | = | -O y,yy,ymm,ypp,yxx |
| c | = | -O c,h,H,hdl,xs |
| c++ | = | -O cpp,CPP,cc,cxx,CXX,h,hh,H,hpp,hxx,Hxx,HXX |
| clojure | = | -O clj |
| cpp | = | -O cpp,CPP,cc,cxx,CXX,h,hh,H,hpp,hxx,Hxx,HXX |
| csharp | = | -O cs |
| css | = | -O css |
| csv | = | -O csv |
| dart | = | -O dart |
| Dart | = | -O dart |
| | | -M '#!\h*/.*\Wdart(\W.*)?\n' |
| delphi | = | -O pas,int,dfm,nfm,dof,dpk,dproj,groupproj,bdsgroup,bdsproj |
| elisp | = | -O el |
| elixir | = | -O ex,exs |
| erlang | = | -O erl,hrl |
| fortran | = | -O for,ftn,fpp,f,F,f77,F77,f90,F90,f95,F95,f03,F03 |
| gif | = | -O gif |
| Gif | = | -O gif |
| | | -M 'GIF87a|GIF89a' |
| go | = | -O go |
| groovy | = | -O groovy,gtmpl,gpp,grunit,gradle |
| gsp | = | -O gsp |
| haskell | = | -O hs,lhs |
| html | = | -O htm,html,xhtml |
| jade | = | -O jade |
| java | = | -O java,properties |
| jpeg | = | -O jpg,jpeg |
| Jpeg | = | -O jpg,jpeg |
| | | -M '\xff\xd8\xff[\xdb\xe0\xe1\xee]' |
| js | = | -O js |
| json | = | -O json |
| jsp | = | -O jsp,jspx,jthm,jhtml |
| julia | = | -O jl |
| kotlin | = | -O kt,kts |
| less | = | -O less |
| lex | = | -O l,ll,lmm,lpp,lxx |
| lisp | = | -O lisp,lsp |
| lua | = | -O lua |
| m4 | = | -O m4 |
| make | = | -O mk,mak |
| | | -g makefile,Makefile,Makefile.Debug,Makefile.Release |
| markdown | = | -O md |
| matlab | = | -O m |
| node | = | -O js |
| Node | = | -O js |
| | | -M '#!\h*/.*\Wnode(\W.*)?\n' |
| objc | = | -O m,h |
| objc++ | = | -O mm,h |
| ocaml | = | -O ml,mli,mll,mly |
| parrot | = | -O pir,pasm,pmc,ops,pod,pg,tg |
| pascal | = | -O pas,pp |
| pdf | = | -O pdf |
| Pdf | = | -O pdf |
| | | -M '\x25\x50\x44\x46\x2d' |
| perl | = | -O pl,PL,pm,pod,t,psgi
| Perl | = | -O pl,PL,pm,pod,t,psgi |
| | | -M '#!\h*/.*\Wperl(\W.*)?\n' |
| php | = | -O php,php3,php4,phtml |
| Php | = | -O php,php3,php4,phtml |
| | | -M '#!\h*/.*\Wphp(\W.*)?\n' |
| png | = | -O png |
| Png | = | -O png |
| | | -M '\x89PNG\x0d\x0a\x1a\x0a' |
| prolog | = | -O pl,pro |
| python | = | -O py |
| Python | = | -O py |
| | | -M '#!\h*/.*\Wpython[23]?(\W.*)?\n' |
| r | = | -O R |
| rpm | = | -O rpm |
| Rpm | = | -O rpm |
| | | -M '\xed\xab\xee\xdb' |
| rst | = | -O rst |
| rtf | = | -O rtf |
| Rtf | = | -O rtf |
| | | -M '\{\rtf1' |
| ruby | = | -O rb,rhtml,rjs,rxml,erb,rake,spec |
| | | -g Rakefile |
| Ruby | = | -O rb,rhtml,rjs,rxml,erb,rake,spec |
| | | -g Rakefile |
| | | -M '#!\h*/.*\Wruby(\W.*)?\n' |
| rust | = | -O rs |
| scala | = | -O scala |
| scheme | = | -O scm,ss |
| seed7 | = | -O sd7,s7i |
| shell | = | -O sh,bash,dash,csh,tcsh,ksh,zsh,fish |
| Shell | = | -O sh,bash,dash,csh,tcsh,ksh,zsh,fish |
| | | -M '#!\h*/.*\W(ba|da|t?c|k|z|fi)?sh(\W.*)?\n' |
| smalltalk | = | -O st |
| sql | = | -O sql,ctl |
| svg | = | -O svg |
| swift | = | -O swift |
| tcl | = | -O tcl,itcl,itk |
| tex | = | -O tex,cls,sty,bib |
| text | = | -O text,txt,TXT,md,rst |
| tiff | = | -O tif,tiff |
| Tiff | = | -O tif,tiff |
| | | -M '\x49\x49\x2a\x00|\x4d\x4d\x00\x2a' |
| tt | = | -O tt,tt2,ttml |
| typescript | = | -O ts,tsx |
| verilog | = | -O v,vh,sv |
| vhdl | = | -O vhd,vhdl |
| vim | = | -O vim |
| xml | = | -O xml,xsd,xsl,xslt,wsdl,rss,svg,ent,plist |
| Xml | = | -O xml,xsd,xsl,xslt,wsdl,rss,svg,ent,plist |
| | | -M '<\?xml ' |
| yacc | = | -O y |
| yaml | = | -O yaml,yml |
| zig | = | -O zig,zon |
|
Filters
A filter utility is associated with one or more filename extensions using the syntax --filter="ext1,ext2,ext3:command". When a filename extension matches a specified filter filename extension ext, then the filter command is executed on the file and the command output is searched instead of the file. Arguments to the specified command may be included and seperated by space. The special command argument % is expanded into the pathname of the file. A command should read the file given by the expanded pathname argument or read the file that is opened as standard input to the command. A wildcard * matches any extension that is not matched by any of the ext specified (matching is case sensitive). Some examples:
- --filter="pdf:pdftotext % -"
- search PDF files, like
ug+
- --filter="doc:antiword %"
- search documents, like
ug+
- --filter="odt,docx,epub,rtf:pandoc --wrap=preserve -t plain % -o -"
- search documents and e-books, like
ug+
- --filter="gif,jpg,jpeg,mpg,mpeg,png,tiff:exiftool %"
- search image metadata, like
ug+
- --filter="odt,doc,docx,rtf,xls,xlsx,ppt,pptx:soffice --headless --cat %"
- search documents, spreadsheets and presentations (this is slow)
- --filter="pem:openssl x509 -passin pass: -text -in %,cer,crt,der:openssl x509 -passin pass: -text -inform der -in %"
- search .pem, .cer, .crt and .der certificates
- --filter="jis:iconv -f SHIFT-JIS -t UTF-8"
- search .jis files encoded in Shift-JIS format converted to UTF-8
- --filter="o,a,so:nm -gU %"
- search object files and libraries for defined symbols
- --filter="*:file %"
- search the file type info of every file using the file utility
- this option is not yet available for the Windows version of ugrep until ugrep 7.1 is released
- the command and its arguments may be quoted (") to include space, comma and % (ugrep v7.1)
- a filter utility should be a command that produces standard output (to search)
- instead of a filename extension alone, it is also possible to specify a file's "magic bytes" regex pattern with --filter-magic-label="LABEL:MAGIC" to associate the MAGIC regex pattern when found at the start of a file with a LABEL to be used as a filename extension in a --filter="LABEL:command"
- UTF-8, UTF-16 and UTF-32 input is automatically searched and does not require a filter
- the Shift-JIS conversion in the example is a special case, option --encoding= supports the arguments
binary, ASCII, UTF-8, UTF-16, UTF-16BE,
UTF-16LE, UTF-32, UTF-32BE, UTF-32LE, LATIN1,
ISO-8859-1, ISO-8859-2, ISO-8859-3, ISO-8859-4,
ISO-8859-5, ISO-8859-6, ISO-8859-7, ISO-8859-8,
ISO-8859-9, ISO-8859-10, ISO-8859-11, ISO-8859-13,
ISO-8859-14, ISO-8859-15, ISO-8859-16, MAC, MACROMAN,
EBCDIC, CP437, CP850, CP858, CP1250, CP1251, CP1252,
CP1253, CP1254, CP1255, CP1256, CP1257, CP1258,
KOI8-R, KOI8-U, KOI8-RU
Colors
The --colors= argument is a colon-separated list of parameters, such as --colors=sl=hy:mt=hyB, where
| sl= | selected lines |
| cx= | context lines |
| rv | swaps the sl= and cx= capabilities when -v is specified |
| mt= | matching text in any matching line |
| ms= | matching text in a selected line, the substring mt= by default |
| mc= | matching text in a context line, the substring mt= by default |
| fn= | file names |
| ln= | line numbers |
| cn= | column numbers |
| bn= | byte offsets |
| se= | separators |
| hl | hyperlink file names, same as --hyperlink |
| qp= | TUI prompt |
| qe= | TUI errors |
| qr= | TUI regex |
| qm= | TUI regex meta characters |
| ql= | TUI regex lists and literals |
| qb= | TUI regex braces |
Multiple SGR codes may be specified for a single parameter when separated by a semicolon, for example --colors="mt=1;31" specifies bright red. For quick and easy color specification, the corresponding single-letter color names may be used in place of numeric SGR codes and semicolons are not required to separate color names, for example --colors=mt=hr specifies bright red. Color letters and numeric codes may be mixed. The following SGR codes have corresponding letter designations:
| 0 | n | normal font and color | 2 | f | faint (not widely supported) |
| 1 | h | highlighted bold font | 21 | H | highlighted bold off |
| 4 | u | underline | 24 | U | underline off |
| 7 | i | invert video | 27 | I | invert off |
| 30 | k | black text | 90 | +k | bright gray text |
| 31 | r | red text | 91 | +r | bright red text |
| 32 | g | green text | 92 | +g | bright green text |
| 33 | y | yellow text | 93 | +y | bright yellow text |
| 34 | b | blue text | 94 | +b | bright blue text |
| 35 | m | magenta text | 95 | +m | bright magenta text |
| 36 | c | cyan text | 96 | +c | bright cyan text |
| 37 | w | white text | 97 | +w | bright white text |
| 40 | K | black background | 100 | +K | bright gray background |
| 41 | R | dark red background | 101 | +R | bright red background |
| 42 | G | dark green background | 102 | +G | bright green background |
| 43 | Y | dark yellow backgrounda | 103 | +Y | bright yellow background |
| 44 | B | dark blue background | 104 | +B | bright blue background |
| 45 | M | dark magenta background | 105 | +M | bright magenta background |
| 46 | C | dark cyan background | 106 | +C | bright cyan background |
| 47 | W | dark white background | 107 | +W | bright white background |
The default color scheme is cx=33: mt=1;31: fn=1;35: ln=1;32: cn=1;32: bn=1;32: se=36: qp=1;32: qe=1;37;41: qm=1;32: ql=36: qb=1;35
Custom output formatting
Formatted output and match replacement puts you in full control of the output. In fact, CSV (--csv), JSON (--json) and XML (--xml) are all produced this way. To produce custom output, specify option --format="FORMAT" with text and the following format fields:
| %% | % |
| %~ | newline (LF or CRLF) |
| %a | basename of matching file |
| %A | byte range in hex of a match |
| %b | byte offset of a match |
| %B %[...]B | text ... + byte offset, if -b |
| %c | matching pattern as C/C++ |
| %C | matching line as C/C++ |
| %d | byte size of a match |
| %e | end offset of a match |
| %f | pathname of matching file |
| %F %[...]F | text ... + pathname, if -H |
| %+ | %F as heading/break, if -+ |
| %h | quoted "pathname" |
| %H %[...]H | text ... + "pathname", if -H |
| %i | pathname as XML |
| %I %[...]I | text ... + pathname XML, if -H |
| %j | matching pattern as JSON |
| %J | matching line as JSON |
| %k | column number of a match |
| %K %[...]K | text ... + column number, if -k |
| %l | last line number of a match |
| %L | number of lines of a match |
| %m | number of matches |
| %M | number of matching lines |
| %n | line number of a match |
| %N %[...]N | text ... + line number, if -n |
| %o | matching pattern, also %0 |
| %O | matching line |
| %p | path to matching file |
| %q | quoted matching pattern |
| %Q | quoted matching line |
| %R | newline, if --break |
| %s | separator (: by default) |
| %S %[...]S | text ... + separator, if %m > 1 |
| %t | tab |
| %T %[...]T | text ... + tab, if -T |
| %u | unique lines, unless -u |
| %[hhhh]U | U+hhhh Unicode code point |
| %v | matching pattern as CSV |
| %V | matching line as CSV |
| %w | match width in wide chars |
| %x | matching pattern as XML |
| %X | matching line as XML |
| %y | matching pattern as hex |
| %Y | matching line as hex |
| %z | path in archive |
| %Z | edit distance cost, if -Z |
| %[...]< | text ... if %m = 1 |
| %[...]> | text ... if %m > 1 |
| %, | , if %m > 1, same as %[,]> |
| %: | : if %m > 1, same as %[:]> |
| %; | ; if %m > 1, same as %[;]> |
| %| | | if %m > 1, same as %[|]> |
| %[...]$ | assign text ... to separator |
| %$ | reset to default separator |
| %[ms]=...%= | color of ms ... color off |
| fields that require option -P for captures |
|---|
| %1 %2 %3 ... %9 | group capture
|
| %[n]# | nth group capture |
| %[n]b | nth capture byte offset |
| %[n]d | nth capture byte size |
| %[n]e | nth capture end offset |
| %[n]j | nth capture as JSON |
| %[n]q | nth capture quoted |
| %[n]v | nth capture as CSV |
| %[n]x | nth capture as XML |
| %[n]y | nth capture as hex |
| %[name]# | named group capture |
| %[name]b | named capture byte offset |
| %[name]d | named capture byte size |
| %[name]e | named capture end offset |
| %[name]j | named capture as JSON |
| %[name]q | named capture quoted |
| %[name]v | named capture as CSV |
| %[name]x | named capture as XML |
| %[name]y | named capture as hex |
| %[n|...]# | capture n,... that matched |
| %[n|...]b | capture n,... byte offset |
| %[n|...]d | capture n,... byte size |
| %[n|...]e | capture n,... end offset |
| %[n|...]j | capture n,... as JSON |
| %[n|...]q | capture n,... quoted |
| %[n|...]v | capture n,... as CSV |
| %[n|...]x | capture n,... as XML |
| %[n|...]y | capture n,... as hex |
| %g | capture number or name |
| %G | all capture numbers/names |
| %[t|...]g | text t,... indexed by capture |
| %[t|...]G | all t,... indexed by captures |
- options -X and -W change the %o and %O fields to output hex and hex/text, respectively.
- option -o changes the %O and %Q fields to output the match only
- options -c, -l and -o change the output of %C, %J, %V, %X and %Y accordingly
- conditional fields such as %B, %F, %K and %N output the separator : after the value, or the separator text assigned with %[...]$
- numeric fields such as %n are left-padded with spaces when %{width}n is specified for width > 0
- matching line fields such as %O are cut to width when %{width}O is specified or when %{-width}O is specified to cut from the end of the line
- character context on a matching line before or after a match is output when %{-width}o or %{+width}o is specified for match fields such as %o, where %{width}o without a +/- sign cuts the match to the specified width
Table of all options that accept format fields:
| --format-begin="FORMAT" | format for beginning the search |
| --format-open="FORMAT" | format for opening a file when a match was found |
| --format="FORMAT" | format for each match in a file |
| --format-close="FORMAT" | format for closing a file when a match was found |
| --format-end="FORMAT" | format for ending the search |
| --replace="FORMAT" | replace matches in the output with the specified format |
- output for --csv is internally produced with
--format-open='%+'
--format='%[,]$%H%N%K%B%V%~%u'
- output for --json is internally produced with
--format-begin='['
--format-open='%,%~ {%~ %[,%~ ]$%["file": ]H"matches": ['
--format='%,%~ { %[, ]$%["line": ]N%["column": ]K%["offset": ]B"match": %J }%u'
--format-close='%~ ]%~ }'
--format-end='%~]%~'
- output for --xml is internally produced with
--format-begin='<grep>%~'
--format-open=' <file%["]$%[ name="]I>%~'
--format=' <match%["]$%[ line="]N%[ column="]K%[ offset="]B>%X</match>%~%u'
--format-close=' </file>%~'
--format-end='</grep>%~'
- to output replaced matches in a file while keeping the rest of the file unchanged, use option --replace="FORMAT" and -y (or --any-line or --passthru)
- to replace matches with corresponding text substitutions, you can use -P "(PATTERN1)|(PATTERN2)|...|(PATTERNn)" --replace="%[TEXT1|TEXT2|...|TEXTn]g" for example -P -iw "(one)|(two)|(three)" --replace="%[ūnum|duo|tria]g"
Indexing
The ugrep-indexer command indexes a directory tree to accelerate searching slow file systems and file systems that are "cold" i.e. not recently cached in memory. Indexing accelerates recursive searching by performing a quick check on precomputed indexes to only search those files that may match.
Indexed-based search with ugrep is safe and never skips new or updated files that may now match. If any files and directories are added or changed after indexing, then ugrep will search these additions and changes made to the file system by comparing file and directory time stamps to the indexing time stamp. When many files were added or changed, then you may want to re-index to bring the indexes up to date. Re-indexing is incremental, it will not take as much time as the initial indexing process.
Please note that indexing is effective for large file systems on slower storage media or when searching many zip and tarball archives. Indexing won't speed up regular file searching on fast nVME SSDs, for example.
- ugrep-indexer -Iz -v
- recursively (re-)index the working directory tree, ignore binary files (option -I), index archives and compressed files (option -z), showing verbose output (option -v)
- ugrep-indexer -Iz -v PATH
- same as above, but (re-)index the specified directory tree PATH
- ugrep-indexer -f -0 -Iz -v PATH
- force full re-indexing with lowest index match accuracy to minimize index files (option -0 for zero, default is -5 for five)
- ugrep-indexer -c PATH
- check the directory tree PATH indexes, the default is to check the working directory tree
- ugrep-indexer -d PATH
- delete the hidden index files from the directory tree PATH, the default is to delete index files from the working directory tree
- ug --index -Iz OPTIONS PATTERN
- perform an index-based recursive search, ignore binary files (option -I), also search archives and compressed files (option -z)
- ug --index -r -Iz OPTIONS PATTERN PATH
- same as above, but perform an index-based recursive search on the specified directory tree PATH
- ug --index OPTIONS PATTERN FILE
- search FILE, but not using an index (only recursive searching is accelerated)
Also...
- ugrep-indexer reads a .ugrep-indexer configuration file when present in the working directory or in your home directory, which should list the names of long options (without the --) to set your preferences
- ugrep-indexer option -v reports progress; to create a log, redirect ugrep-indexer -v output to a log file
- ugrep-indexer option -S follows symlinks to files; indexing never follows symlinks to directories
- ugrep-indexer option -X or --ignore-files obeys .gitignore rules
- ugrep-indexer options -z --zmax=2 indexes nested archives and tarballs (two levels)
- ug option --index works with all other search options, except for options -P, -Z, -v and --filter
- ug option --stats reports index-based search details, including false positives; false positives are reduced with higher indexing accuracy and/or by using more specific search patterns
Bugs
If you found a bug or an issue, then please report it at https://github.com/Genivia/ugrep/issues
License
Ugrep is open source BSD-3 licensed:
| Permissions |
|---|
| ✔️ commercial use |
| ✔️ modification |
| ✔️ distribution |
| ✔️ private use |
| Limitations |
|---|
| ❌ liability |
| ❌ warranty |
| Conditions |
|---|
| ⓘ include license |
| ⓘ copyright notice |
Ugrep is written by Robert A. van Engelen, Copyright (c) 2026 Robert A. van Engelen, Genivia Inc.
The ugrep author received the 🏆 Google Peer Bonus Award 2022 for developing ugrep
Ugrep project repo: https://github.com/Genivia/ugrep ⭐️ thank you for starring the project!
Ugrep uses the RE/flex regex library: https://github.com/Genivia/RE-flex
Ugrep option -P uses the PCRE2 library: https://www.pcre.org
See also: gnu grep, bsd grep, git grep, pcre grep, agrep, ack, ag, rg, sift
Last updated: Sat May 23, 2026